一般Agent和图博定制Agent有什么区别
企业AI Agent通用和定制差在哪?9个维度看清差距
2025 年是 Agent 爆发元年,2026 年 Agent 已经成了企业 AI 的标配。但很多企业用了半年发现:Agent 搭了,效果不行。
问题不在 Agent 这个概念,而在 Agent 的"深度"。市面上大多数 Agent 是通用型——能对话、能调用工具、能自动执行流程。但到了真实业务里,它不懂你的行业规则、不知道老员工怎么判断、更不知道你的系统里数据长什么样。
今天从图博数智做过的项目经验出发,讲清楚一般 Agent 和图博定制 Agent 到底差在哪。
一、先说结论:9 个维度,差距一目了然
| 维度 | 一般 Agent | 图博定制 Agent |
|---|---|---|
| 知识深度 | 基于公网通用数据,无法理解企业内部知识 | 深度整合企业私有数据,懂你的业务语境 |
| 业务理解 | 只会聊天,不懂行业规则和岗位 SOP | 通过「岗位能力封装」将业务规则植入系统,按标准执行 |
| 系统能力 | 独立工具,与企业 ERP/MES/CRM 数据不通 | 直连核心业务系统,打通数据与流程闭环 |
| 执行能力 | 只能回答问题,无法自动执行业务流程 | 端到端自动执行:报价、解析、质检、出报告 |
| 经验沉淀 | 对话用完即走,老员工经验无法积累 | 专家经验自动沉淀为结构化知识资产 |
| 输出质量 | 依赖 prompt 水平,输出不稳定、不可控 | 标准化输出,结果可追溯、可验证 |
| 数据安全 | 数据上传外部服务器,存在泄露风险 | 支持私有化部署,数据不出企业 |
| 数据溯源 | 输出黑盒,无法追溯结果来自哪里 | 数据溯源 + 过程溯源,输出原始文档和每步处理链路 |
| 技术底层 | 依赖第三方平台,无法自主控制底层 | 自有技术底层框架,支持深度定制与迭代 |
一句话概括:一般 Agent 是"智能客服",图博定制 Agent 是"数字员工"。
二、知识深度:公网数据 vs 私有知识库
一般 Agent 的知识来自大模型的训练数据和公网检索。你问它行业术语,它能解释;你问它"我们公司上个月的质检合格率是多少",它答不上来。
图博的做法是先建私有知识库——把企业的历史文档、技术规范、项目档案、实验数据全部结构化入库。Agent 每次回答,不是靠"猜",而是从你的私有数据里检索。
在高校科研场景里,这一点尤其关键。通用模型经常捏造参考文献或 DOI,导致 AI 生成的结果无法在课题论证中使用。图博帮南京大学构建的 MatSeek 科研平台,基于私有知识围栏和深度语义检索,检索精准度做到 95% 以上,搜出来的文献可以直接引用。
差异本质:一般 Agent "知道很多",图博 Agent "知道你的"。
三、业务理解:聊天机器人 vs 岗位能力封装
这是图博和一般 Agent 最大的区别。
一般 Agent 的交互方式是"你问我答"。你问得越精确,它答得越好。问题是你不可能每次都写出完美的 prompt。而且不同人对同一个问题的描述方式不一样,输出质量参差不齐。
图博的方法叫**「岗位能力封装」**——把某个岗位的业务规则、SOP、判断标准、老员工经验,直接"写死"到 Agent 的行为逻辑里。
举个实际例子。在制造企业的报价环节,一个有经验的报价员看到客户图纸,脑子里会自动走一套判断流程:材料类型 → 工艺要求 → 公差等级 → 历史相似件成本 → 附加系数。这套判断不是写几句 prompt 就能教给通用 Agent 的。
图博的做法是把这套"报价员大脑"拆解成结构化的决策树,注入到 Agent 里。它不是在"聊天",而是在"按标准执行"。
差异本质:一般 Agent 靠 prompt 驱动,图博 Agent 靠业务规则驱动。
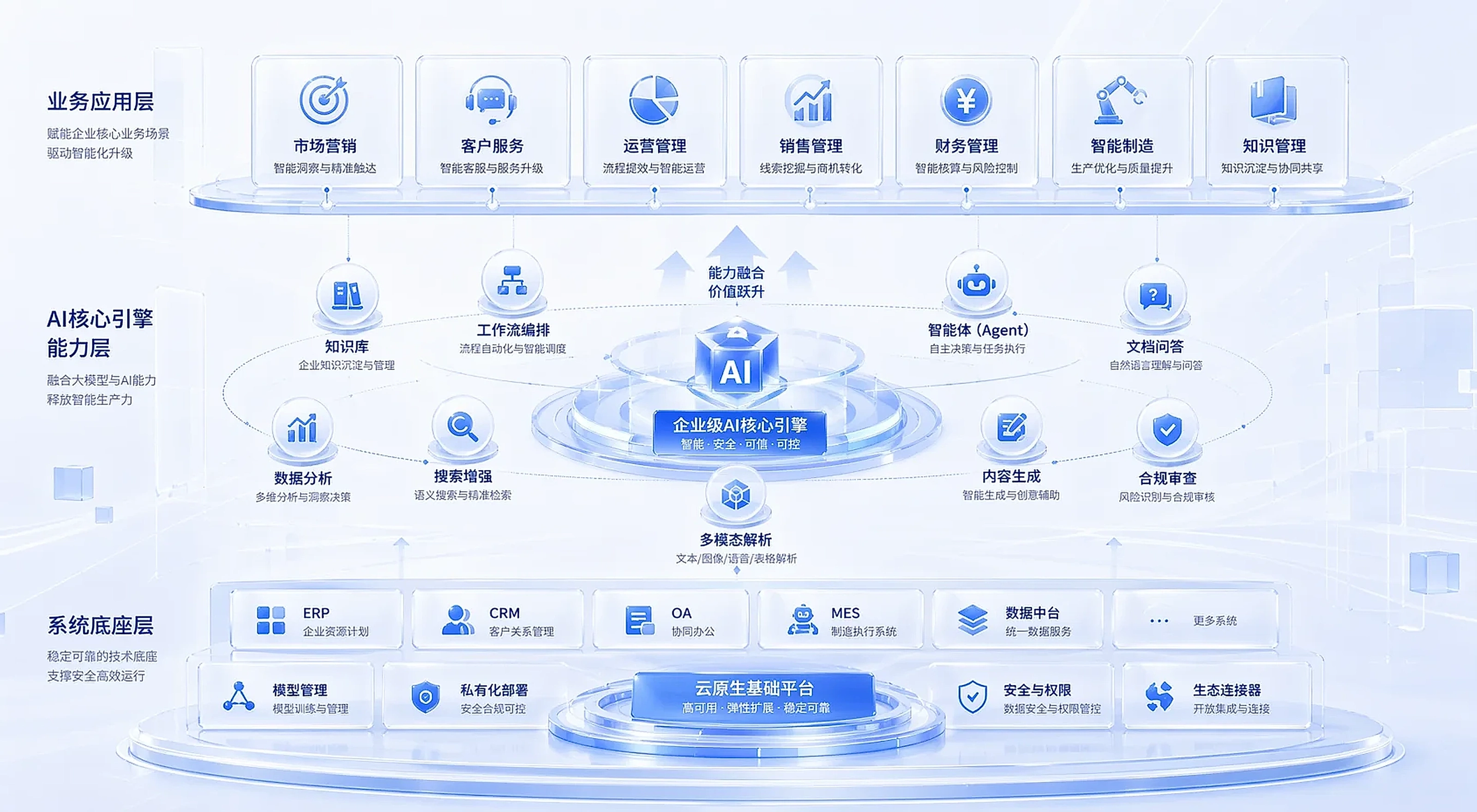
四、系统能力:独立工具 vs 流程闭环
一般 Agent 是独立运行的。它能帮你写文案、做总结、回答问题,但它和你公司的业务系统是割裂的。
图博定制 Agent 会直接接入你的 ERP、MES、CRM、OA 等核心系统。Agent 不是站在系统外面"提建议",而是走进系统里面"干活"。
比如在南通华为电力的项目中,图博的 Agent 做到了:自动读取客户图纸 → 解析技术参数 → 匹配历史报价 → 生成报价方案 → 推进生产排程。从报价到生产,整个流程 Agent 在系统内端到端跑通。
在高校场景里,图博的五大智能体模块覆盖了科研 + 论文 + 教学 + 行政 + 财务全流程。不是只帮你查文献,而是从知识库构建、科研探索、论文写作、课堂教学到行政管理,形成完整闭环。
差异本质:一般 Agent "站在旁边建议",图博 Agent "跑在流程里面"。
五、经验沉淀:用完即走 vs 知识资产化
一般 Agent 用完就结束了。今天的对话不会让明天的 Agent 更聪明。
图博定制 Agent 有一个持续积累的机制:每次执行任务的过程和结果,都会被结构化记录,自动沉淀为组织的知识资产。
在科研场景里,这意味着课题组的每一轮实验数据、每一次推理验证的结论、每一篇文献的分析结果,都会被系统记录和复用。新加入的研究生不需要从零开始,前人的研究路径就在知识库里。
在制造企业里,老员工的判断标准、常见的异常处理方法、典型的报价决策逻辑,都被 Agent 学习和保存。人走了,经验留下了。
差异本质:一般 Agent 是"消费品",图博 Agent 是"投资品"。
六、数据安全与溯源:外部托管 vs 私有部署
一般 Agent 的数据跑在第三方服务器上。对企业来说,这意味着核心业务数据离开了企业的控制范围。
图博支持私有化部署,所有数据不出企业、不出校园。这在高校科研和制造业场景里尤其重要——科研数据、客户报价、技术参数,这些都不能放到外部。
另外,图博 Agent 的每一次输出都能溯源——不是黑盒式的"答案",而是附带原始文档引用和处理链路的"证据"。科研人员可以直接验证 Agent 给出的推理是否可靠,质检员可以追溯到每一个判断的数据依据。
差异本质:一般 Agent "给你答案",图博 Agent "给你证据"。
七、多 Agent 协作:不只是"一个 Agent"
图博的 Agent 不是孤立的。在一些复杂场景里,图博会设计多 Agent 协作架构。
比如在日化配方研发中,图博设计了五个专业 Agent 组成的"科研飞轮":
- 策略 Agent:筛选候选原料
- 计算 Agent:输出配比方案
- 实验 Agent:生成实验 SOP
- 分析 Agent:建模性能关系
- 推理 Agent:输出优化建议
五个 Agent 闭环协作,从策略到计算到实验到分析到推理,形成持续迭代的研究循环。
在高校平台里,图博同样采用五大模块协同:知识库是基座,科研智能体、论文智能体、教学智能体、行政财务智能体各司其职又数据互通。
差异本质:一般 Agent 是"单兵作战",图博 Agent 是"团队协作"。
八、最后说一句实话
Agent 不复杂,复杂的是业务。
很多企业觉得 Agent 没效果,不是 Agent 技术不行,是 Agent 没有真正理解你的业务。
通用 Agent 解决的是"能不能对话"的问题,图博解决的是"能不能干活"的问题。
我们图博数智这几年一直在帮企业和高校做AI落地的活儿,从AI知识库、智能体到私有化大模型部署,踩了不少坑也攒了不少经验。如果你所在的单位正在考虑AI落地,可以直接加图老师聊聊。

